
How does NVIDIA Confidential Computing impact inference and training performance?
We’re frequently asked how much overhead confidential computing imposes on inference and training. At Tinfoil we run every model privately inside a hardware enclave, and pay this tax on every token we serve, so this isn't just an academic question for us.
In this post, we publish what we believe are the first public benchmarks for confidential computing on NVIDIA’s Blackwell architecture, as well as for the previous-generation Hopper. Before we measured anything, we went looking for measurements that already existed. The public work stops at single-GPU Hopper[1], [2], with only one paper analyzing multi-GPU Hopper[3] (with emulated drivers). We also had a year of measuring CC overhead alongside our partners for multi-GPU Hopper: inference for Llama with Meta, post-training for Kimi K2-Thinking with Workshop Labs, and interpretability in vLLM-lens with Pour Demain. But for Blackwell, there was nothing at all. Even NVIDIA’s Blackwell technical brief states that CC delivers “nearly identical throughput” to unencrypted mode, but does not publish the underlying measurements.
So we ran the measurements ourselves, across workloads and configurations, focusing on production-oriented environments. Our benchmarking setup includes a full confidential VM, with Intel TDX + NVIDIA CC mode, running inference engines like vLLM, SGLang, and TRT-LLM, plus training workloads on NVIDIA's NeMo AutoModel harness. We found some predictable and some surprising results. On Blackwell, CC impacts inter-token latency anywhere from ~1% with a CC-aware engine, to ~30% with a CC-naive engine in compute-bound regimes, to over 100% at low concurrency. Training throughput is impacted 18–32%.
Our goal is to map the overheads that surface in production CC workloads, tie each back to its specific architectural root, and leave you with a clear mental model of what to look for when understanding and optimizing for performance when using confidential computing.
The entire investigation builds up to one idea, so if you remember one thing, it is that:
GPU math is free. Crossing an encrypted link, whether with data, a command, or just a synchronization signal, is taxed in CC mode.
Communication between the CPU and GPU is less efficient under CC. All communication has to go through a staging area, known as the bounce buffer. This bounce buffer is responsible for the majority of direct and indirect sources of overheads when CC is enabled, since all instructions and data have to go through it. This bounce can indirectly force synchronization and affect pipelining of instructions, lowering throughput unless directly corrected for.
Much of this overhead can be dealt with by optimizing the workload at the application layer, though this deviates from the promise of NVIDIA CC being entirely “lift-and-shift”. We can observe this directly by comparing the CC overheads for inference engines such as TRT-LLM or SGLang that have been optimized by NVIDIA (CC-aware) vs. ones that have not, such as vLLM (CC-naive). We also anticipate later versions of NVIDIA drivers will move some of these optimizations into the driver runtime, eliminating the need for application-level awareness of CC. This is also a problem that will be solved once ecosystem support for hardware-accelerated inline device encryption, called TEE I/O or TDISP, is implemented, such as in the Linux kernel.
This is a long post that covers a lot of ground:
- First, we discuss where the confidential computing costs come from. What is encrypted, what isn’t, and how that changes across GPU generations.
- Second, we discuss how inference and training work, and how these tolls materialize in practice through end-to-end benchmarks.
- Third, microbenchmarks that can help us understand how the end-to-end tolls on inference and training actually break down.
- Fourth, how costs scale across variables. What variables stay put, and for the ones that don’t, how do they scale.
- Finally, what are some strategies you can undertake to reduce these overheads.
1. What’s encrypted, and what isn’t
Before we start, a quick recap of what GPU architecture looks like:

To explain what needs to be encrypted under confidential computing, we need to distinguish between what is “on die” and “off die” on the hardware. The threat model of confidential computing assumes any data outside the die boundary can be read and written by an adversary with access to the host machine. It follows that all off-die values need to be encrypted and authenticated before leaving the GPU or CPU private memory for the system to be secure.

Specifically, there are three things that are encrypted:
- CPU's memory
- Data crossing between the CPU and the GPU over the PCIe bus that connects them
- Links between GPUs (NVIDIA's NVLink, Blackwell and later)
Notice that the tensor cores and HBM are both out of the picture! Once data and instructions are loaded into the GPU, there is basically no CC penalty for computation.
The bounce buffer: the main source of overhead in CC
How does data, such as the model's inputs and outputs, or instructions, move between the CPU and GPU memory?
Without CC, data and instruction transfer happens using direct memory access (DMA). But in CC mode, the GPU isn't allowed to reach directly into the CPU's encrypted memory. The solution here is to use a mechanism that’s called the bounce buffer. Effectively, every byte from the CPU or guest private memory is encrypted and takes a detour (a “bounce”) through a shared staging area on the host (for instance, using Linux SWIOTLB), before the GPU's hardware fetches and decrypts it on the other side. GPU-to-CPU transfers follow the same path in reverse. The extra encryption and copy operations are the principal costs.

2. An end-to-end view of CC tolls
Quick overview of inference and training
Inference
Let’s understand how inference happens without CC so we can build a theory on where CC penalties might show up. The GPU handles an inference request in two phases:
- Prefill: reading your prompt. The model ingests all tokens from the entire prompt at once, in parallel. This is one big burst of arithmetic and it keeps the GPU busy. It produces the first token.
- Decode: generating the response. The model then generates the answer one token at a time, and each token depends on the previous one, so generation can't be parallelized.

This gives us two common metrics used to characterize LLM performance:
- “Time to First Token” or “TTFT”, which measures the prefill time plus one decode step to generate the first token.
- “Inter-Token Latency” or “ITL”, which measures the delay time between each output token generation.
This is just an overview. To dive deeper, we recommend this article on optimizing LLM performance.
Training
A training run is composed of often millions of steps. Each step does a forward pass (the model reads a whole batch at once and makes predictions, in one big parallel burst, much like prefill), then a backward pass (it traces the error back through every layer to work out how each weight should change, which involves more large-scale arithmetic, roughly double the forward pass), then a small update that nudges the weights.

If the model is split across several GPUs, they also sync up once per step to agree on a single combined update. Training is characterized by big, GPU-saturating chunks of compute end to end (here we watch throughput, not latency).
What are the CPU and GPU communicating about?
To see when the bounce buffer is used, and where to expect costs, we first need to understand how the CPU and GPU work together. The GPU doesn’t act on its own; it’s driven by the CPU. The CPU submits commands: run this computation, copy that buffer, or wait for this work to finish.

During regular, non-CC operation, the CPU writes these commands into a queue in host memory called the pushbuffer. The GPU DMAs those commands and then fetches the referenced data separately.

Going through each scenario:
- During prefill, the system stages the prompt and some required metadata onto the GPU (host to device, or H2D), performs a large compute-heavy forward pass, then may return a small amount of result data to the host (D2H).
- During decode, each step stages small control and metadata updates (H2D), runs the model and sampling work, then returns the generated token to the host (D2H).
- During training, most communication and memory copying is between GPU ↔ GPU.
Now, in CC mode, everything needs to go through a bounce buffer, so we would expect all commands and data transfers to simply pay some fixed cost because they cannot be sent with DMA.
Spoiler: there’s more than that, but let’s first observe what actually manifests in practice before we start to analyze details.
Setup and method
We benchmarked 8×B300 SXM6 AC (Blackwell) and 8×H200 (Hopper) systems inside Intel TDX guests, using 128-vCPU guest configurations for the main runs. Captured provenance reports NVIDIA driver 595.71.05, driver-reported CUDA 13.2, CUDA runtime/toolkit 13.0.88, PyTorch 2.11.0+cu130, and NCCL 2.28.9. Engine versions were vLLM 0.21.0 (Kimi and Hopper Gemma), vLLM 0.22.0 (the B300 Gemma single-GPU run), SGLang 0.0.0.dev1+gf7d4e44d8, TRT-LLM 1.3.0rc18, and NeMo AutoModel 0.5.0 with Transformers 5.8.1.
Every overhead number compares CC-on vs CC-off within the same engine, model, workload shape, and GPU configuration; the toggle changes the full confidential stack, meaning GPU confidential mode plus Intel TDX memory encryption. Inference figures are generally one benchmark run per point per mode, reported from successful-request medians or means, with repeated Gemma engine rows collapsed by median. Training figures use one run per mode and report median steady-state throughput after warmup, typically over 80-100 measured steps depending on recipe.
End-to-end inference overheads
We’ll now look end-to-end at ITL (decode). The lower the ITL, the more tokens generated per second, so throughput is roughly the inverse of ITL.
Inter-token latency (ITL)
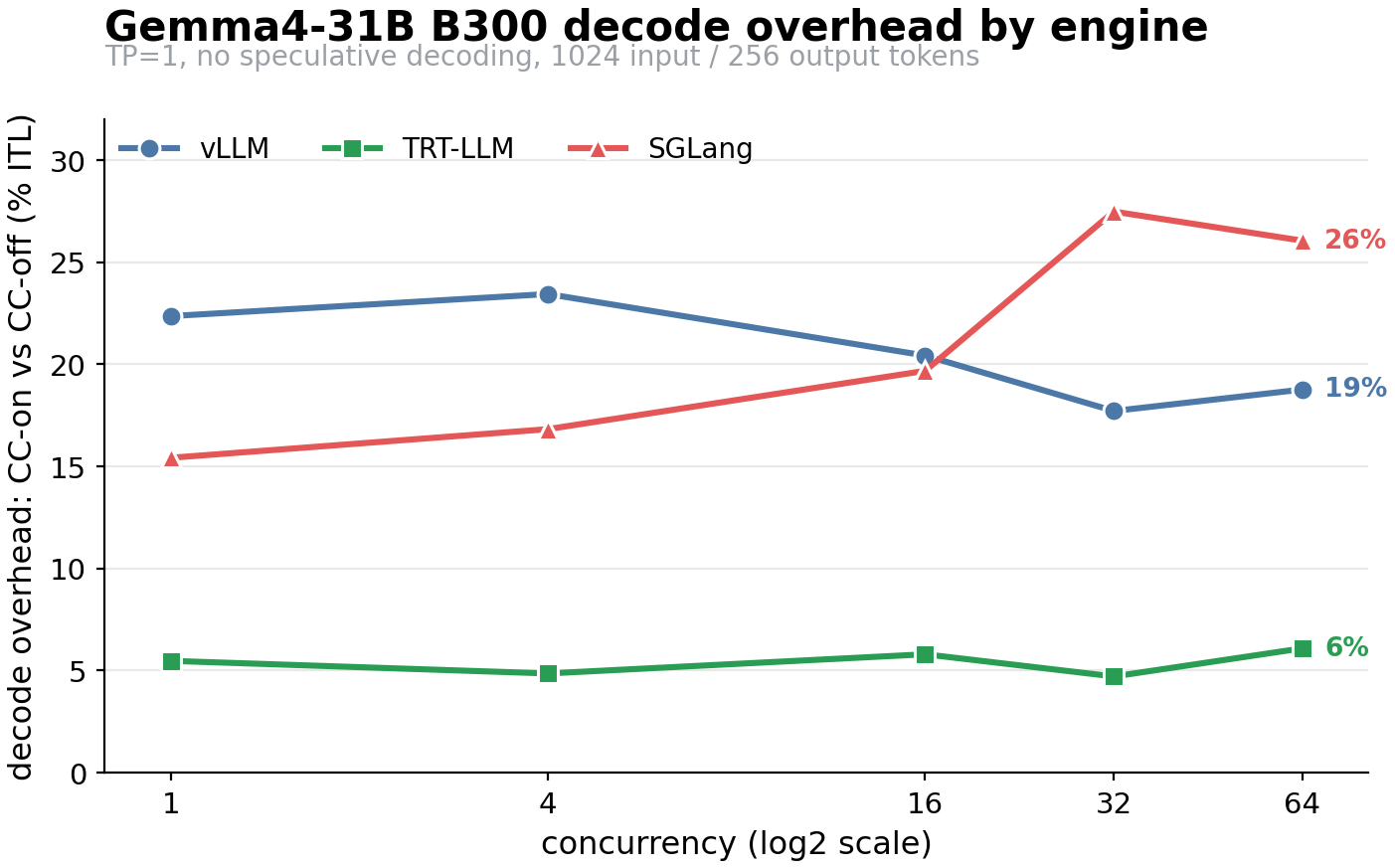
To start with, let’s take Gemma 4 31B inference on a single B300. We measured this with three different implementations: the default vLLM (CC-naive), an NVIDIA-optimized TRT-LLM implementation (CC-aware), and an NVIDIA-optimized SGLang implementation (CC-aware).
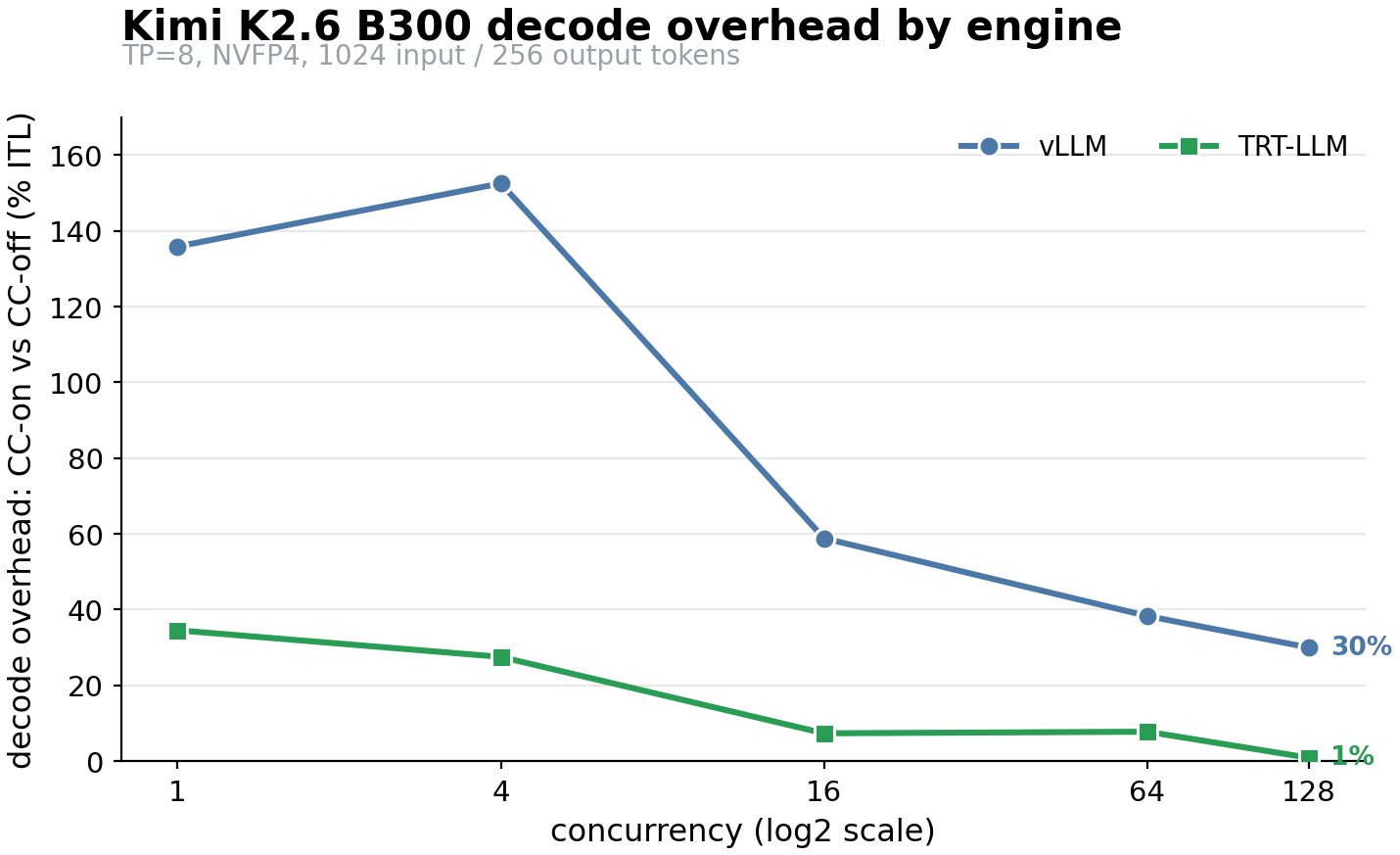
Next, we take a look at Kimi K2.6 TP=8 inference on 8×B300.
All together, across Hopper and Blackwell, with vLLM (CC-naive):

We can see the end-to-end overheads for ITL can range from 30% in compute-bound regimes (high concurrency), to over 100% in low-concurrency regimes.
The important point here is that the overhead for vLLM is much higher than we would expect from a simple fixed cost imposed by the bounce buffer. Additionally, with a CC-aware implementation such as TRT-LLM, we see that this cost can go down as low as 1% for even larger models, which our bounce-buffer fixed-cost model doesn’t predict. We have to go deeper.
End-to-end training overheads
Meanwhile, training under confidential computing is slower, but not in a simple “everything gets 30% worse” way. A useful way to think about it is that CC adds a toll around the edges of each training step: launching GPU work, moving data across protected CPU/GPU boundaries, touching encrypted host memory, and coordinating communication. If the step is doing a lot of real GPU math, that toll gets spread over more useful work. If the step is lighter, the toll becomes a bigger fraction of the total time.
That is why LoRA, which trains only a very small fraction of total parameters compared to full SFT, tends to look worse than full SFT in our measurements. LoRA makes training cheaper by updating only a small set of adapter weights, but the system still has to do much of the same orchestration around every step, so the proportional cost is higher.
In our runs, Gemma 4 31B LoRA on 8×H200 kept about 0.68× of plaintext throughput, while full SFT kept about 0.82×. Llama 3.3 70B on 8×B300 showed the same pattern: LoRA kept about 0.70×, while full SFT kept about 0.79×. Put differently, full SFT gives the confidential-computing overhead more compute to hide behind, while LoRA exposes it more clearly.
| Model | Platform | Recipe | Throughput loss |
|---|---|---|---|
| Gemma 4 31B | 8×H200 | LoRA: gemma4/gemma4_31b_peft.yaml | 32.3% |
| Gemma 4 31B | 8×H200 | Full SFT: gemma4/gemma4_31b.yaml | 18.0% |
| Llama 3.3 70B | 8×B300 | LoRA: llama3_3/llama_3_3_70b_instruct_squad_peft.yaml | 29.7% |
| Llama 3.3 70B | 8×B300 | Full SFT: llama3_3/llama_3_3_70b_instruct_squad.yaml | 21.0% |
3. Micro-benchmarks
Looking at the end-to-end inference and training overhead numbers, we see some results that our bounce buffer understanding alone fails to predict. Aspects such as increasing concurrency lowering ITL overheads are expected, and a result of more compute amortizing communication costs. However, some of the most interesting results are:
- CC overheads are larger on Blackwell than Hopper.
- CC-aware implementations can provide a large improvement over CC-naive implementations.
It’s time to dig deeper by bench-marking the microscopic building blocks that make up a compute workload. Since all overheads should come from communication over a link (CPU ↔ GPU or GPU ↔ GPU), let’s go through them one by one.
Control path (CPU to GPU over PCIe)
The most common command during model execution is a kernel launch: “run this GPU function now.” Whether it is a prefill, decode, or training step, each can involve hundreds to thousands of such kernel launches.
We measured the time it takes to execute a kernel launch, and observe that each kernel launch is 3-4x slower on Blackwell under CC.
| Operation (Blackwell B300) | CC off | CC on | slowdown |
|---|---|---|---|
| issue one kernel launch (pipelined launches + one final sync) | 7.4 µs | 26 µs | 3.5× (Hopper: ~2.0×) |
| launch + wait for the result (serialized launch + sync/wait for completion) | 14 µs | 55 µs | 3.9× (Hopper: ~2.6×) |
That sounds catastrophic: hundreds to thousands of kernel launches per step, with each launch several times slower under CC. This creates a lot of back and forth between the CPU and the GPU.
Luckily, CUDA graphs provide an “escape hatch”. Instead of sending every single kernel launch command across the CPU-GPU boundary, which we call eager mode (expensive), you can record a fixed sequence once as a "graph" on the GPU and replay it using a single command (cheap), amortizing the launch cost across all the kernels inside the graph. Luckily, CUDA graphs are usually the default, but to illustrate our point, running vLLM in eager mode added roughly 25-35 extra percentage points of decode overhead compared with the default CUDA-graph path. A previous post that discussed overheads for interpretability tooling, which was forced to run in eager mode, is another case in point.
The above kernel launch numbers also explain why Blackwell overheads look worse than Hopper. Blackwell pays roughly 4× on each launch; Hopper pays about 2.5×. The major discontinuity occurs between one GPU and two GPUs, when using Blackwell’s multi-GPU mode. Hopper does not show the same discontinuity. Specifically, multi GPU Blackwell overhead was 2x that of single GPU Blackwell. Meanwhile, single GPU and multi GPU Hopper overheads were roughly equivalent.
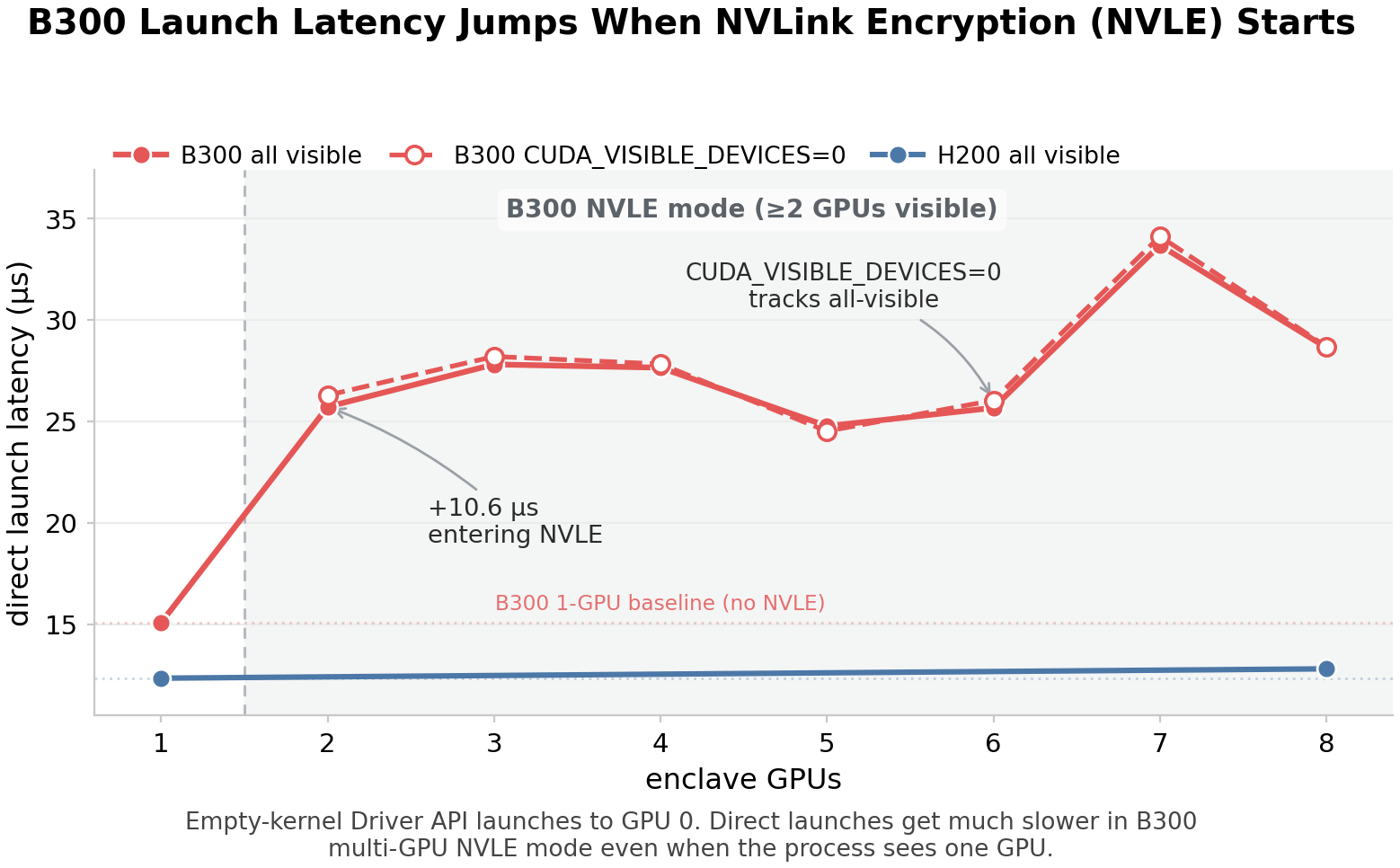
The reason for this is a bit of mystery to us, and something that can be better answered by NVIDIA. What we did observe was that most of the overhead was not coming from the encryption itself, but the setup before the encryption.
Data path (CPU to GPU over PCIe)
For instance, one of the reasons why TRT-LLM (which was optimized for CC) significantly outperforms vLLM (which wasn’t optimized for CC), is because it replaces some pinned memory for CPU to GPU communication (which uses DMA) with pageable memory in CC. In particular, see the TRT-LLM optimization NVIDIA/TensorRT-LLM#11573.
The headline finding here inverts standard GPU advice. Normally you use "pinned" memory, which is host memory locked in place so the GPU can pull from it directly through DMA to make CPU-GPU transfers fast. Under CC, the pinned fast path collapses, keeping only about 20% of its plaintext speed, to the point that the normally slower path becomes the faster one. The reason for this is that the "transfer" involves the CPU core doing encryption in software (as opposed to having hardware-accelerated encryption) before writing data into the bounce buffer.
| CPU→GPU transfer (Blackwell B300) | CC off | CC on | bandwidth kept |
|---|---|---|---|
| pinned memory (the usual "fast path") | 55.7 GB/s | 4–11 GB/s | ~0.20× |
| pageable memory (the ordinary path) | 19.2 GB/s | 15.0 GB/s | 0.78× |
For generating text one token at a time, this crossing is actually a minor cost, because only a few kilobytes move per token. But it can be more significant during bulk transfers, such as when loading a terabyte of model weights at startup, or during prefill, or during training.

An interesting question here is: why is pinned memory through bounce buffer more expensive than pageable memory through bounce buffer? This is yet another question that only NVIDIA can answer definitively. Our best guess is that the pinned path is not optimized for CC.
Async device-to-host copy effectively becomes sync
Decode has a small but important readback at the end of each step: the GPU produces the sampled token, and the CPU-side scheduler needs to learn what happened.
Normally this readback can be issued with cudaMemcpyAsync. That does not mean the data is available immediately. It means the scheduler can enqueue the copy and keep going while the GPU and copy engine finish the work in the background. The copy is still ordered correctly by CUDA, but the scheduler thread is not forced to stop right there.
That matters because decode is a tight per-token loop. The scheduler needs to stay free to prepare the next step, launch the next CUDA graph, handle other requests, and only wait for the token when it truly needs it. In the good case, the tiny readback does not become a hard CPU/GPU barrier on every token.
Under CC, that changes. The GPU cannot directly DMA results into the guest’s private host memory. The data has to go through the protected bounce-buffer path: GPU-side encrypted/staged output first, then CPU-side work to make it available in the guest’s private memory. In practice, the cudaMemcpyAsync readback can stop behaving like a quick enqueue and start behaving like a blocking call.
The expensive part is not that decrypting a sampled token is large work. The expensive part is where the wait lands. If the scheduler blocks inside the readback, it cannot launch the next decode step while the current one is finishing. The GPU completes step N, but step N+1 is not ready to run yet because the scheduler was stuck in the copy call. A tiny readback has turned into a per-token serialization point.

This is why the NVIDIA and SGLang CC-aware patches matter. Both TRT-LLM and SGLang avoid letting the main scheduler thread pay this blocking copy directly. They move the readback onto a separate worker thread. The copy may still block somewhere, but it blocks the worker, not the scheduler. The scheduler can keep preparing and launching decode work, and consumers wait for the token only when they actually need it.
So the core issue is not “D2H copies are big.” They are usually tiny. The issue is that, under CC, a tiny async readback can become a synchronization point in the hottest part of the decode loop.
That is one reason vLLM decode overhead can look worse than TRT-LLM or SGLang when those systems use CC-aware readback paths.
Data path (GPU to GPU over NVLink)
A GPU node consists of 8 GPUs connected over NVLink, which is NVIDIA’s proprietary networking fabric for high-speed data transfer across GPUs within a node (and within a rack, for Vera Rubin). When a model is too big to fit on a single GPU, it is spread across several GPUs. These GPUs then have to constantly communicate with one-another to swap partial results. This communication is done over NVLink, which happens many times over for every single token the model outputs.
There’s a few different variations of how models or data can be spread across GPUs, with some strategies requiring more or less frequent communication across links. These are tensor parallel, data parallel, expert parallel or pipeline parallel.
In Hopper, confidential mode leaves the NVLink wire unencrypted (it fences the GPUs off as a group rather than encrypting the cable between them). This means when GPU ↔ GPU communication happens, the data over the NVLink wire is not encrypted. In Blackwell, however, it is encrypted. So our guess would be that any overheads for GPU ↔ GPU communication would be limited to Blackwell. Counterintuitively, that turns out not to be the case. Instead, we observe that the overhead is roughly the same for both Blackwell and Hopper.
In particular, the bandwidth barely suffers (it keeps about 89% of plaintext), but every exchange pays a fixed toll of roughly 10–15 microseconds. Because there are so many exchanges per token, that fixed per-exchange toll adds up. And despite not having NVLink encrypted, Hopper has roughly the same toll as Blackwell. So the overhead isn't simply coming from the wire encryption, which checks out with NVIDIA mentioning that Blackwell wire encryption operates at near-native speeds.
| measurement | Blackwell (NVLink encrypted) | Hopper (NVLink in plaintext) |
|---|---|---|
| per-exchange latency toll, small messages (≤1 MB) | +10–15 µs | +9–13 µs |
| large-transfer bandwidth kept | 0.89× | 0.94× |
What's left is a fixed setup cost the GPU pays to dispatch each cross-GPU operation while it's in confidential mode. This is per-operation bookkeeping done by the secure firmware, incurred whether the message is tiny or large. We can show it's there, that it's per-operation, and that it's the same on both GPU generations; the exact internal cause lives inside NVIDIA's closed firmware. The takeaway is that it's a fixed cost per cross-GPU operation, and it is not wire encryption. This is a firmware-level change, that’s baked into the architecture of how NVIDIA Confidential Computing works, so it’s harder to optimize at a software level.
Compute cannot happen in NVSwitch (or, multicast disabled on Blackwell)
However, there is yet another issue: CC also disables the CUDA multicast operation on Blackwell. Multicast on NVLink is provided by NVLink SHARP (NVLS), which allows some amount of computation to happen in the NVSwitch itself. However, in Blackwell, NVSwitch is outside the trust boundary and therefore cannot operate on plaintext data. This is in contrast to Hopper, where the NVSwitch is in the trust boundary. So multicast gets turned off in CC mode for Blackwell, and collectives such as all-reduce fall back to point-to-point encrypted NVLink (NCCL ring/tree over P2P). For instance, NVIDIA patched SGLang to replace a multicast workspace requirement with ordinary shared GPU memory, allowing a “fused” kernel to run under CC instead of falling back to slower unfused operations. CC_FIXES.md (related PR: sgl-project/sglang#28251)
As an example, multicast accelerates an all-reduce across GPUs, which fires after every layer in tensor-parallel inference and training. First, the slow path, without multicast:

Above, each GPU ships its shard across the fabric, the partial sums bounce around to all other GPUs, and the GPUs themselves need to do computation doing the addition. Now the same all-reduce with multicast:

Now the work has moved into the switch, and the GPUs are doing almost nothing. Two things drop sharply: NVLink bandwidth, because data is sent up once instead of looping around the ring, and GPU compute (Streaming Multiprocessor) usage, because the reduction arithmetic happens inside the switch ASIC rather than on the GPUs.
The biggest real-world payoff is tensor-parallel LLM serving and training, where an all-reduce fires after the attention and MLP blocks of every layer; collapsing each of those into a single in-network reduce both saves bandwidth and frees SMs so the communication can overlap with compute. It does little for point-to-point or all-to-all patterns (e.g., expert-parallel MoE dispatch), which don't map onto a reduce/broadcast.
This is yet another component in the explanation for why Hopper multi-GPU has less overhead compared to Blackwell multi-GPU.
4. Costs at scale
Given our mechanistic understanding, the overhead should respond to real-world knobs in specific, predictable ways as compute workloads scale to production levels. Remember that more time spent computing vs communicating is better for overheads, so we should expect larger batch sizes or larger model sizes to be better.
Batch size: more requests at once → less overhead
On Blackwell, multi-GPU decode overhead falls monotonically as concurrency rises:
| load | inter-token latency overhead | decode throughput kept |
|---|---|---|
| 1 request, short prompts (worst case) | +118% | 0.52× |
| 4 requests, short prompts | +99% | 0.52× |
| 16 requests, long prompts | +69% | 0.63× |
| 32 requests, long prompts (best case) | +49% | 0.70× |
At the worst case, aka a single request, ITL more than doubles and you keep only about half your decode throughput (you'd need nearly 2× the GPUs for the same output rate). Pile on load and it eases toward +49% / 70% kept. This implies a fixed per-step tax being diluted by compute.
Prompt size: larger prompt size is better
| Workload (input/output tokens) | CC off tok/s | CC on tok/s | CC keep ratio (throughput) | CC loss (overhead) |
|---|---|---|---|---|
| 128/128 | 569.3 | 444.1 | 0.78× | 22.0% |
| 8192/512 | 272.4 | 242.4 | 0.89× | 11.0% |
For Gemma 4 31B running on a single B300, at the same concurrency, moving from the short workload to the long workload roughly halves the confidential computing throughput penalty, from 22% to 11%. That suggests the fixed CC overhead is being amortized better when each request contains more GPU work.
Parallelism: the more GPUs you split across, the worse it gets

Splitting a model across more GPUs means more cross-GPU exchanges per token and each one pays toll (ii). So wider splitting should cost more under CC. It does. On the same model (Kimi K2.6, vLLM, 8×B300), comparing TP=4 against TP=8:
| load | TP=4 (kept) | TP=8 (kept) |
|---|---|---|
| 1 request | 0.59× | 0.46× |
| 4 requests | 0.64× | 0.43× |
| 128 requests (saturated) | 0.73× | 0.68× |
The narrower split keeps more of its plaintext performance at every load, and the gap is widest at small batch, which directly traces back to "more cross-GPU operations = more fixed tolls paid." This also maps to multicast being disabled.
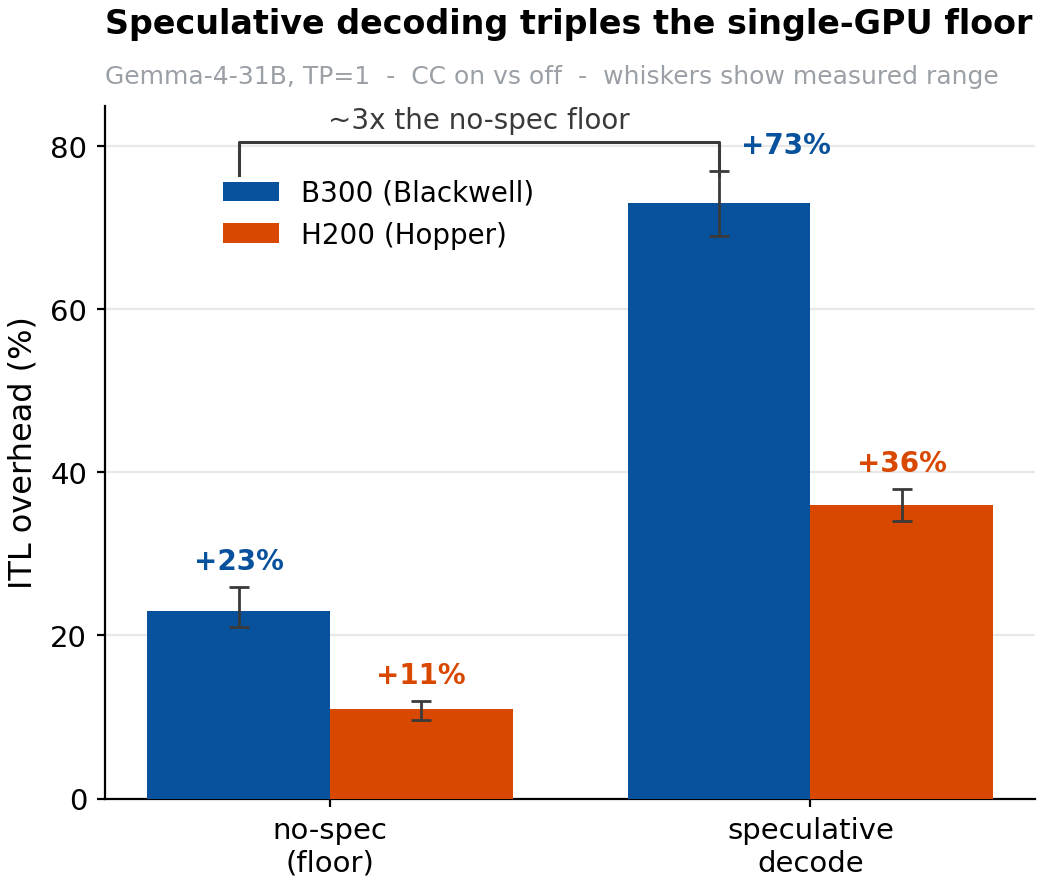
Speculative decoding: a clever speedup that can be disproportionately impacted by CC
"Speculative decoding" allows you generate tokens faster by guessing several ahead and checking them in a batch. But it adds extra CPU↔GPU round trips per token. This means it should be disproportionately expensive under confidential computing.
We find that it is. Turning it on roughly triples the single-GPU overhead, from the ~21–26% floor up to ~70% on Blackwell.
5. How to actually reduce the overhead of CC
Given all this information, what is the optimal way to structure your workload to reduce CC overheads? This obviously depends on the workload, but we’ll go step by step through some rule of thumbs we came up with while optimizing things ourselves:
- Batch aggressively. The overhead is dominated by fixed per-step tolls that dilute as you add work. The compute-bound, high-concurrency regime is where CC is cheapest; the saturated figures (approx. 14% on Hopper, approx. 25–30% on Blackwell) are reasonable capacity-planning numbers. The worst case is one-request-at-a-time latency.
- Use a larger model. Llama3.1 8B suffers from 8% overhead for throughput vs 1% for Llama3.3 70B, on single-GPU H200. We’ve seen this pattern broadly replicate.
- Prefer a narrower model split with more replicas for latency-sensitive serving. An 8-way split pays more cross-GPU tolls than two 4-way replicas serving the same traffic, and the difference is large at low load (keeping ~0.6× vs ~0.45× of throughput).
- Always use CUDA graphs; never run eager. This is the big one. Recording per-step commands into a graph turns the 3–4×-per-launch command toll into a one-time cost. Running eager pays the toll on every one of those hundreds to thousands of launches, every step, instead of amortizing them into a graph, which is the most expensive mistake you can make under CC.
- Don't reach for the usual "pinned memory" optimization for CPU-GPU transfers; it collapses under CC, and the ordinary path is faster.
- Re-evaluate speculative decoding. Make sure to profile it under CC because it multiplies the taxed crossings.
- Rewrite kernels to not rely on multicast. Many kernels that may not use much of multicast (but might use some) might get automatically disabled if multicast is not available, rendering many of the performance optimizations in them also underutilized. Rewrite the kernels to remove the multicast specific portion while still allowing your implementation to take advantage of the rest of the kernel.
Closing thoughts
Confidential compute is great, and surprisingly performant given the benefits of verifiability and privacy. However, getting the most out of it requires some effort to make your implementation CC-aware and performant.
At Tinfoil we’re interested in making CC as easy to use and ubiquitous as possible. In that interest, and following in NVIDIAs footsteps with TRT-LLM and patching SGLang, we’ve made some preliminary strides on vLLM (reducing Gemma’s overhead by 40% in some experiments). We’ll talk more about this in a follow-up post, so stay tuned!
It’s also important to remember that the bounce buffer architecture is not permanent. The next step in confidential computing (inline encryption at the device boundary, "TEE-I/O") is designed to remove those detours, at which point the gap to NVIDIA's compute-bound numbers should close substantially.
Another interesting observation has been that Hopper had less CC overhead than Blackwell. The two main sources here are the additional kernel launch time and removal of NVSwitch from the trust boundary (which is good for security!) but has the unfortunate side effect of disabling multicast. We expect the kernel launch time be fixable, while the disabling of multicast is more structural.
We hope this post serves as a useful reference to anyone interested in running production AI workloads in CC mode. If you have questions or supplementary results and benchmarks, we’d love to chat!
Subscribe for Updates
RSS FeedStay up to date with our latest blog posts and announcements.