Auditing a Frontier Model Without Seeing its Weights
Frontier AI labs are accumulating capabilities that increasingly resemble those of a nation state. Unlike nation states, mechanisms for accountability remain limited. While black box access through the API is available to anyone who wants to audit a model, deeper access, such as access without classifiers, access to chain of thought, or even access to model internals: the activations, representations, weights - is heavily restricted.
Frontier model labs will sometimes provide trusted organizations such as METR, CAISI, and UK AISI with more privileged access to models. The level of access here varies, and can be insufficient as many failure modes are only discovered with whitebox access to model weight internals. See: Black-Box Access is Insufficient for Rigorous AI Audits.
The biggest reason why frontier labs are reluctant to share more privileged access to model weights with external parties is security and the risk of model weight/architecture leakage. Even model metadata such as size of weights, size of serving code and so on, can be highly sensitive. Reciprocally, an external auditor may not want to fully share their evaluation criteria with the labs in order to ensure a fair evaluation with verification that the audit was run appropriately.
Verifiable Clean Rooms
One way to make this sort of collaboration more palatable is to use a Verifiable Clean Room. A verifiable clean room is a way for mutually untrusted parties to run a workload they've both agreed on, where each keeps its inputs private and both get cryptographic proof of exactly what ran. In this case, the auditor brings the eval (a dataset plus the code to run it) and the lab brings its model weights (and inference harness). Secure enclaves with verifiable attestation provide a mechanism to construct such a clean room. The eval runs against the weights inside the enclave; the weights never leave the enclave; the auditor comes away with only the results that were produced by an agreed-upon computation.
When we learned that Alejandro Tlaie Boria from Pour Demain, a Brussels-based AI policy think tank, was working on gray box evaluations of frontier model weights using enclaves, we were eager to collaborate and Tinfoil Containers turned out to be the right platform to make it happen.
Pour Demain's whitepaper details an architecture where a provider and an auditor can collaborate to run evals, in a verified, secure environment. Data access & egress controls are used to restrict and monitor the data being exported. The proposed evaluation architecture is a harness that allows for limited white box access (activation capture, representation steering, expert-routing analysis, input gradients).
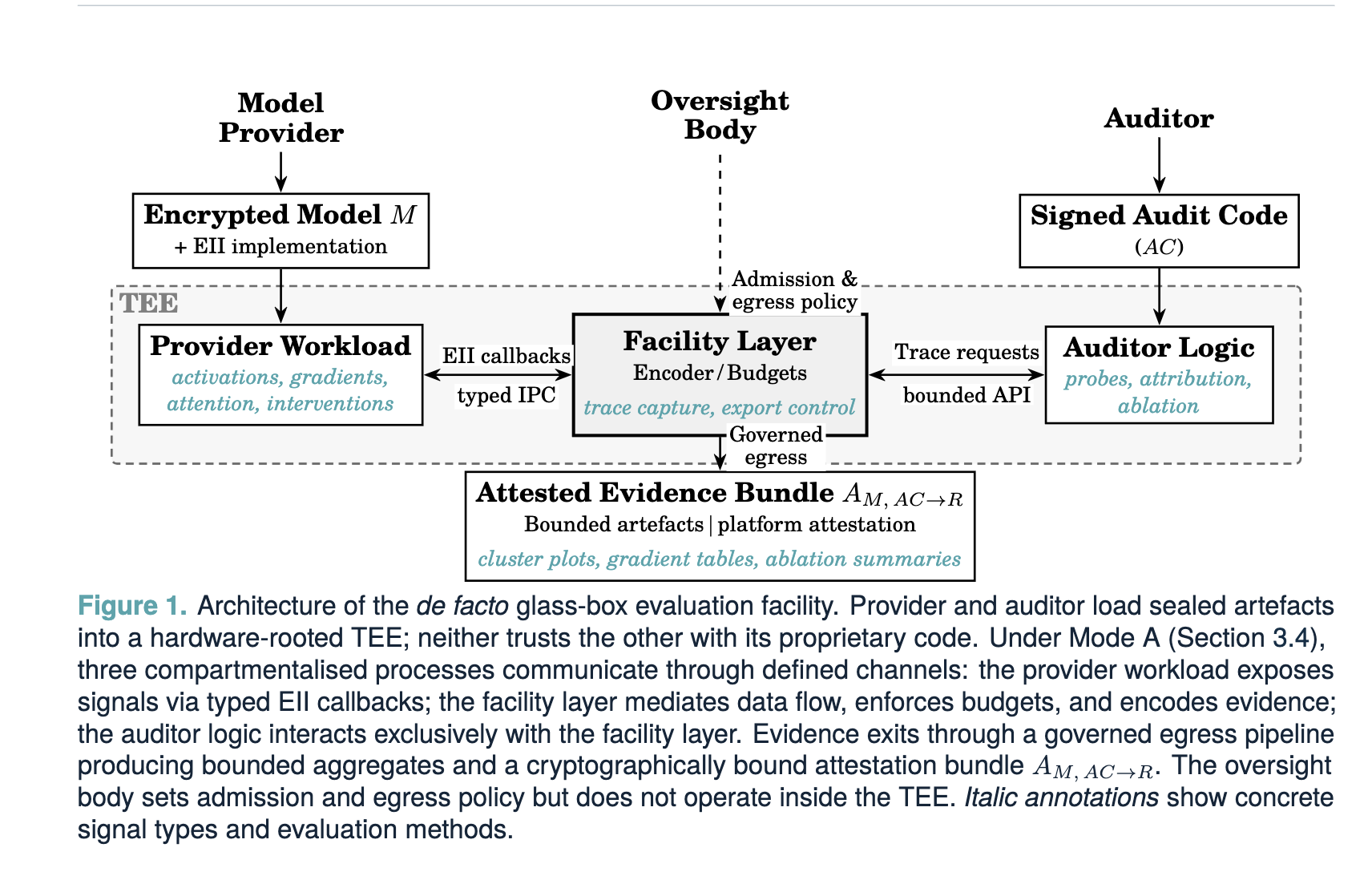
Diagram taken from Pour Demain's whitepaper
Verifying what is running is great for all parties involved:
- Auditors know they're testing the correct weights.
- The company owning the weights gets a guarantee that the weights are safe.
- Auditors can prove what evaluations they were running, while keeping trade secrets private.
Using Tinfoil Containers, Pour Demain's newest technical brief shows the feasibility of using vllm-lens, an open-source interpretability library from UK AISI, in confidential enclaves to evaluate models. They also demonstrate the access control & governance layer outlined in their whitepaper.
Measured Interpretability Overheads
They measured 33-38% overhead when running GLM-5.1, a ~744 billion parameter model, on confidential computing (across eight H200 GPUs) with vllm-lens interpretability hooks attached.
That's higher than typical from confidential computing. On production inference, NVIDIA's confidential computing adds about 5-7%. The rest comes from the interpretability tooling, and how the model has to run for the tooling, the way it's currently designed, to work.
Some background. A GPU relies on the CPU to feed it instructions one operation at a time when it runs a model. Generating one token takes hundreds of these. Issuing them individually is wasteful, so vLLM normally uses a trick called CUDA Graphs: it records the full sequence for a decode step once, then replays the recording with a single instruction per token. This significantly reduces the number of round trips between CPU and GPU.
vllm-lens works by attaching hooks, which are small pieces of Python that copy out the model’s internal activations as each layer runs. A replayed recording never runs that Python since it’s a pure-GPU rerun of the captured operations. So to see inside the model, vllm-lens has to turn the recording off and run every step the slow way (with more back and forth between CPU and GPU).
That’s slower everywhere, with or without CC. But CC makes it disproportionately worse, because of where CC’s costs live. The GPU’s compute and memory run at full speed under CC, but the communication between the CPU and GPU is what’s impacted due to encryption. You can visualize this as a toll at the border: the toll itself is small, and with CUDA Graphs, it's paid a minimal number of times for a decode step. Meanwhile without CUDA Graphs, that number jumps up significantly.

Breaking the overhead down by configuration:
| Configuration (same in both arms) | CC off | CC on | CC delta |
|---|---|---|---|
| Stock vLLM, CUDA Graphs on | 0.445 s | 0.494 s | +11.1% (GLM: +6.7% — the "5–7%" band) |
| Stock vLLM, eager, no vllm-lens | 1.589 s | 2.114 s | +33.1% |
| vllm-lens (eager + plugin) | 1.567 s | 2.168 s | +38.3% (GLM: +33.4%) |
So there are two places the overhead could be coming from: (a) the hooks/plugin code, or (b) the eager mode the plugin forces (which is one mechanism vLLM provides to disable CUDA Graphs). Running stock vLLM in eager mode isolates (b) and it reproduces +33.1%, nearly the whole effect. Hence: the hooks contribute a few points at most; eager mode is what makes the workload CC-sensitive. Some of this is fixable with vllm-lens design that’s aware of CC. vLLM can keep just the hooked layers in eager mode and leave the rest on graphs. This is left as future work. The important result for Pour Demain is that naive (to confidential compute) implementations work well enough.
Verification beyond privacy
We built Tinfoil Containers to make exactly this kind of work possible. The part of attestation we find most compelling is that it answers two questions at once: not only "can anyone see this data?" but "is the system doing what it claims?" That second guarantee is what lets an auditor and a lab agree on the same computation without having to trust each other, and it is why we think confidential computing belongs in evaluation and oversight, and shouldn't just be limited to privacy-preserving applications.
We're very interested in seeing this applied more with AI. As an emerging, powerful technology we want to make sure it's beneficial to humanity. Ensuring it goes well is too important of a task to entrust only to the hands of a few opaque organizations. To this end, we need external verification, and we're hoping that technologies such as Verifiable Clean Rooms can reduce the friction around it.
If you're working on AI evaluation, verifiable governance infrastructure, or safeguards you'd want to run inside someone else's enclave, please reach out!
Subscribe for Updates
RSS FeedStay up to date with our latest blog posts and announcements.