
How Tinfoil Proves Exactly What Model Is Running
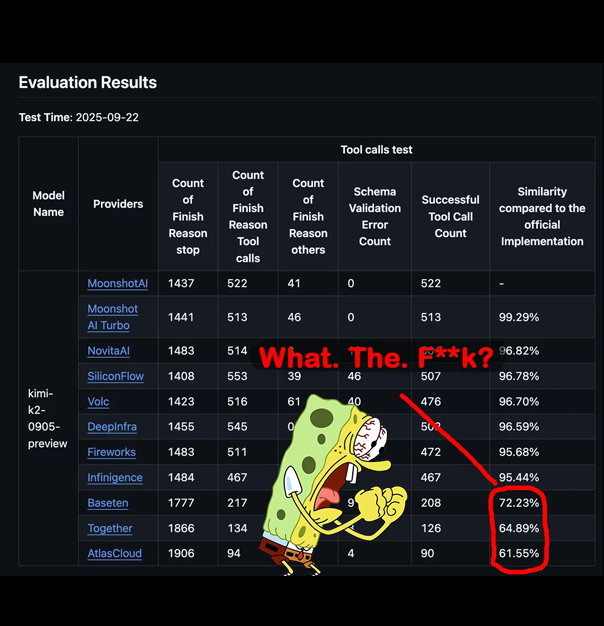
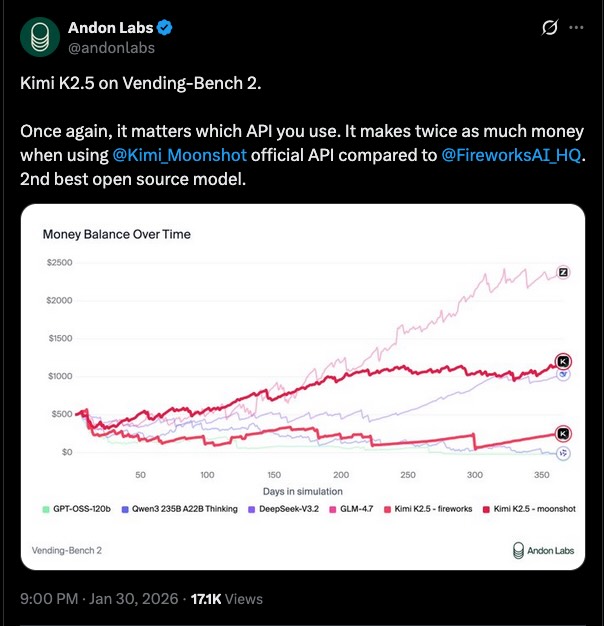
When you call an inference API, how do you know which model you're actually served? Sure you can specify the name of the model you expect to process your request, but ultimately you have no guarantee that the provider is actually serving it.
When talking to an open-source model, are you being served the exact weights that the model publisher released on Hugging Face? Or is it a silently quantized version, or a version with a smaller context window that changes based on how much traffic the provider is experiencing?
The situation gets even murkier when using a closed-source model provider. How do you know that you are getting the same model each time?
People routinely report wide variation in evals across providers (and sometimes across time within the same provider, see Claude Opus performance tracking). And sometimes, accidental misconfigurations can silently degrade quality.
Verifiable Inference with Modelwrap
At Tinfoil, we built Modelwrap, which is a way to cryptographically guarantee that we are serving a specific, untampered set of weights that our clients can verify on each request. This is a very strong guarantee that so far we have not seen any other inference provider offer. At its core, Modelwrap consists of the following components:
- A public commitment to model weights
- A mechanism to bind the public commitment to the inference server
- A process to verify, client-side, that the inference server is using the committed model weights
In this post, we go into the technical details of how we built Modelwrap.
Why is this harder than just vanilla attestation?
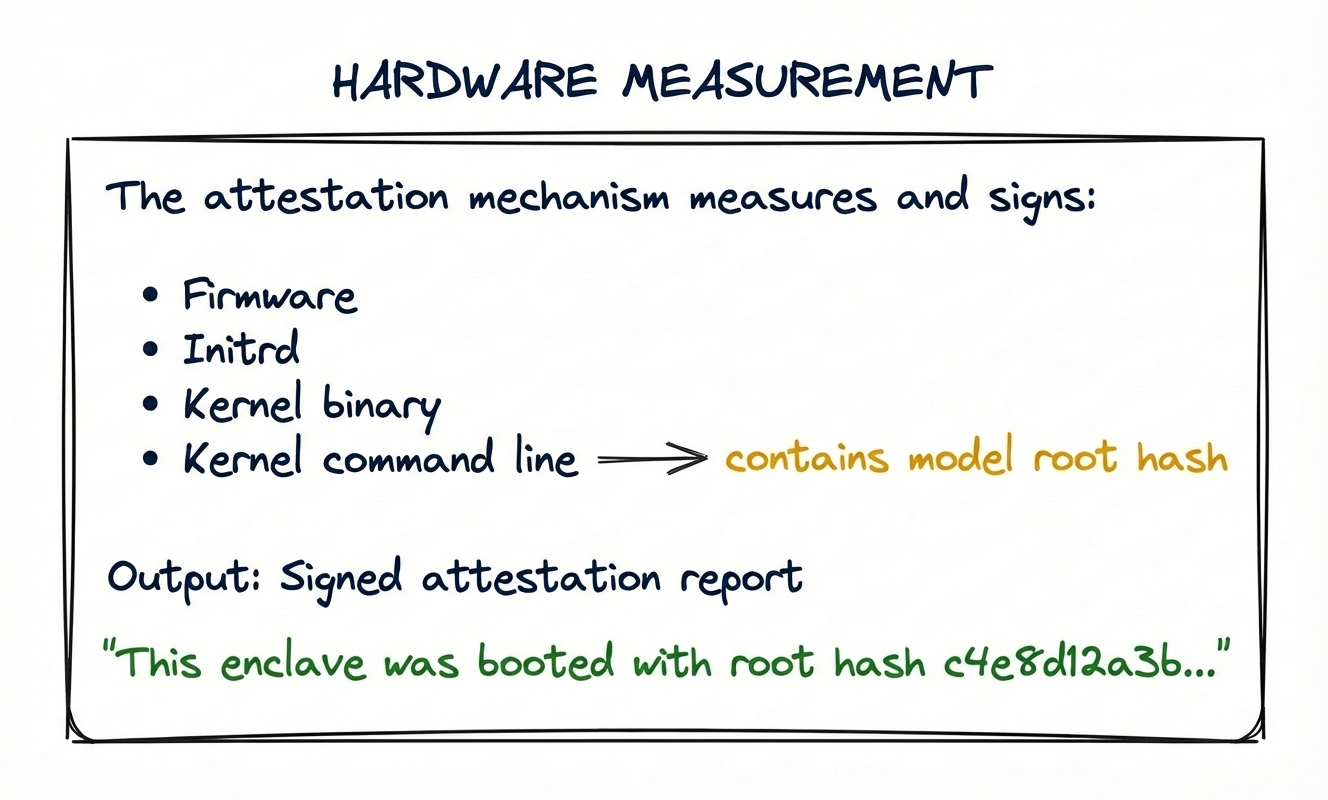
We run models in secure hardware enclaves, which already allow us to prove which code we're running inside the enclave through attestation. In a nutshell, the way that attestation works is by measuring the initial state of the machine at launch time. When you boot an enclave with a given binary, the hardware produces a signed report that proves exactly what binary was loaded.
But attestation measures launch state, not runtime state. Weights are loaded from disk storage after the enclave has already booted. If you rely on basic attestation, the attestation report will not include this post-boot loading from disk storage. So the real problem becomes:
How do we make attestation meaningfully bind to data that is fetched later?
The trick is to attest that the enclave includes both the expected hash of the data and some code that will check that hash after it's loaded. With Modelwrap we end up attesting two things:
- The cryptographic commitment to the model weights (a single root hash via a Merkle tree)
- The enforcement mechanism that checks the commitment (kernel-level verification on every read via dm-verity)
We're still using boot-time attestation, but now the attestation process proves that "the system is configured so that it cannot read bytes that don't match the committed hash," which provides a runtime guarantee. The enforcement mechanism we use under-the-hood is called dm-verity, a kernel-level system for verifying cryptographic commitments of read-only filesystems.
Building Blocks
Before diving in, we need to explain the building blocks that make up Modelwrap.
Merkle Tree
Suppose the model weights are 140GB. We would like to prove that "these are exactly the weights we publicly committed to". A Merkle tree lets you authenticate large amounts of data (140GB) with a small commitment (32 bytes). The idea is to split the data into fixed-size blocks of 4KB each, then hash pairs of those hashes together, and keep going until you're left with a single root hash. If any part of the data changes anywhere, the root hash also changes. Such a hash tree makes it easy to verify any single block corresponds to the commitment at read time: all we need is to check hashes along the path from the block to that root.
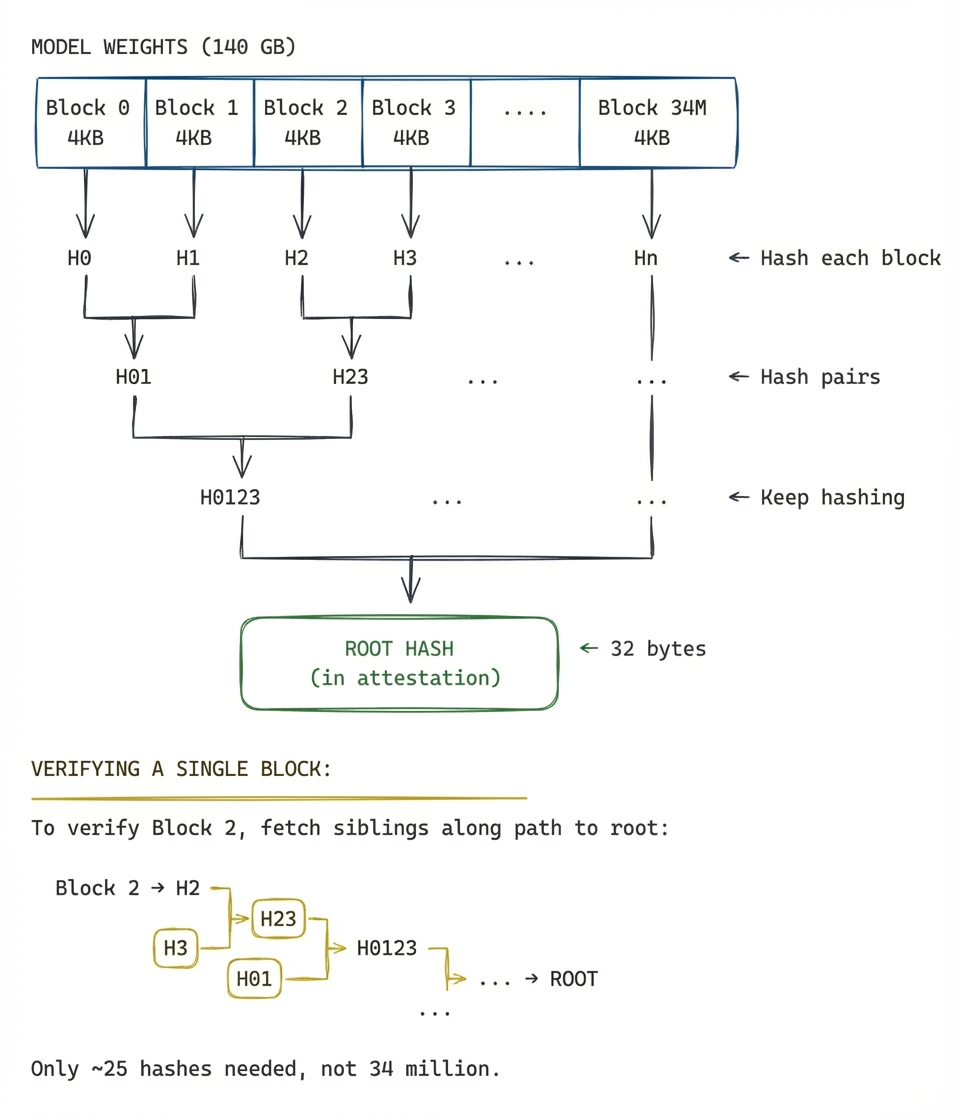
Merkle trees are commonly used in situations where large amounts of data must be verified piecewise such as in Certificate Transparency and Sigstore.
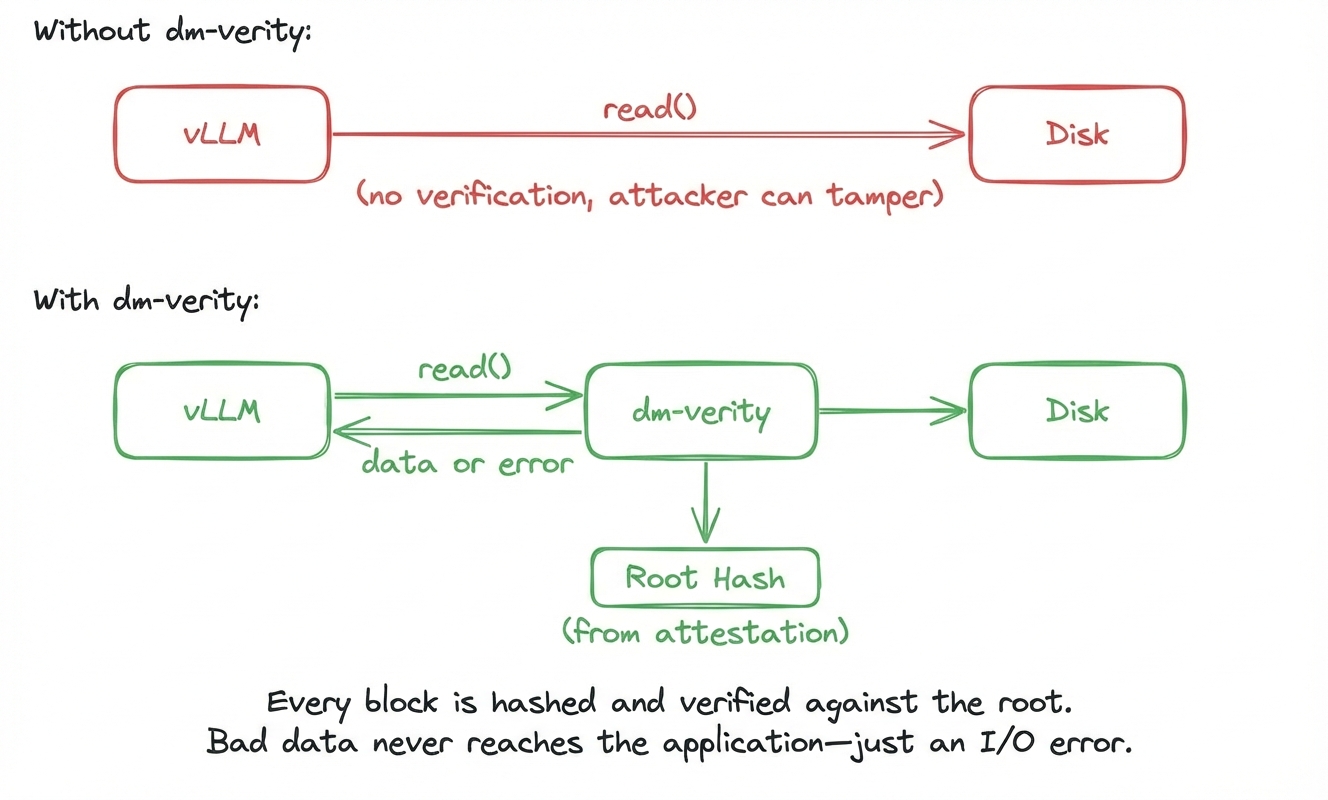
dm-verity
The Merkle tree gives us a way to verify any block with one root hash.
But that alone won't stop anyone from reading bad data. Something needs to
actually enforce verification on every read. This is where dm-verity comes in.
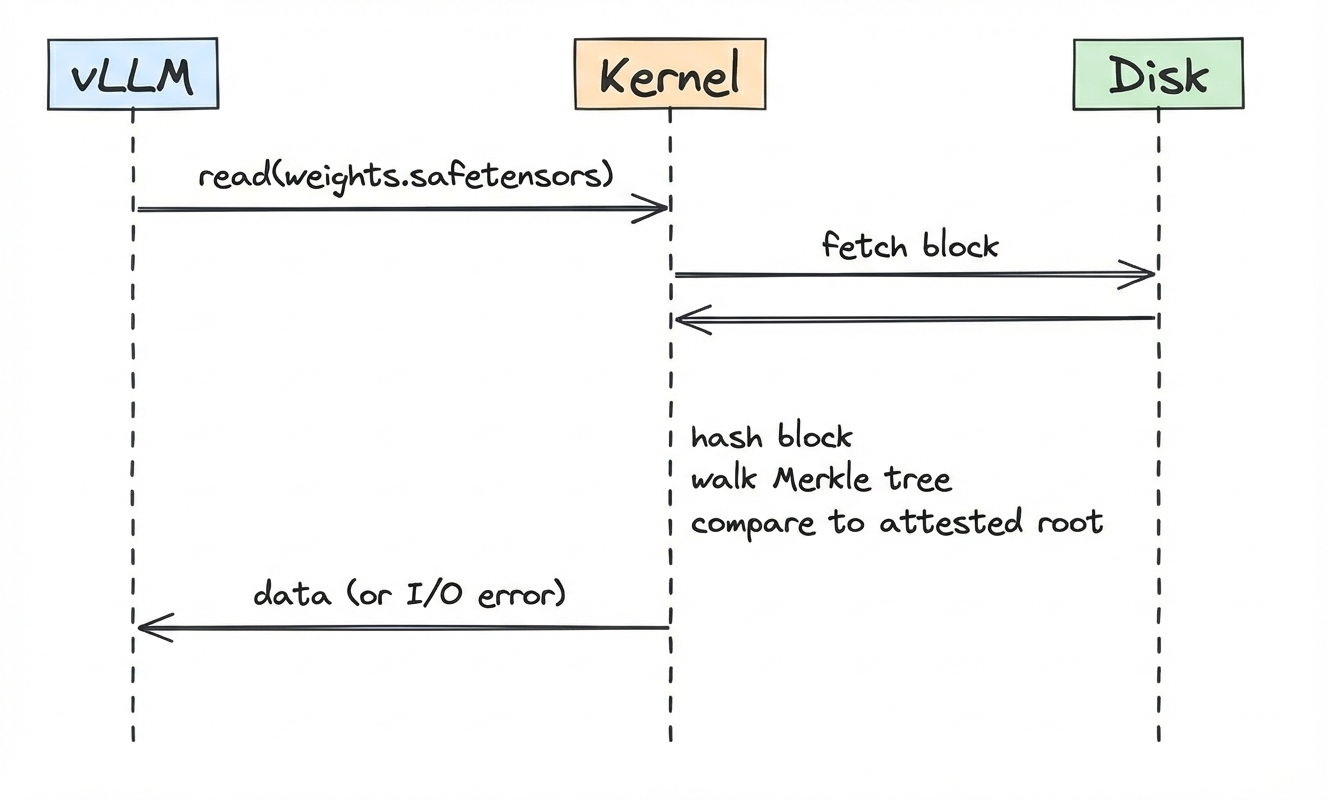
dm-verity is a Linux kernel subsystem that verifies disk reads using a Merkle
tree. When the inference server (such as vLLM) calls read() to load model
weights, dm-verity automatically intercepts the request, fetches the block,
hashes it, walks the Merkle tree to the root, and compares against the provided
root hash. If there's a match, it returns the data. If there is no match, it
returns an I/O error and the application never receives the corrupted block.
We want to emphasize that the magic of dm-verity is that vLLM (or any application doing the reads) has no idea this verification is happening! This means there is no need for code changes or special APIs. Everything happens transparently at the kernel level. If the weights don't match the committed root hash, it simply becomes impossible to read from disk and the application gets an I/O error.
This is how Android verified boot has worked since 2013. The bootloader passes a trusted root hash to the kernel. Every block read from the system partition gets checked against the hash tree. Billions of devices use this to catch any disk tampering today.
Modelwrap Architecture
Modelwrap uses a combination of dm-verity and read-only filesystems to create what's called an "attested disk". This is a standard technique used in confidential computing for OS image integrity. For instance, this pattern was used by Confidential Containers for OS and Amazon Linux attestable AMIs.
Our main insight behind Modelwrap is that model weights have the same properties as OS images because (1) they're large, (2) read-only at inference time, and (3) in our case need strong integrity guarantees.
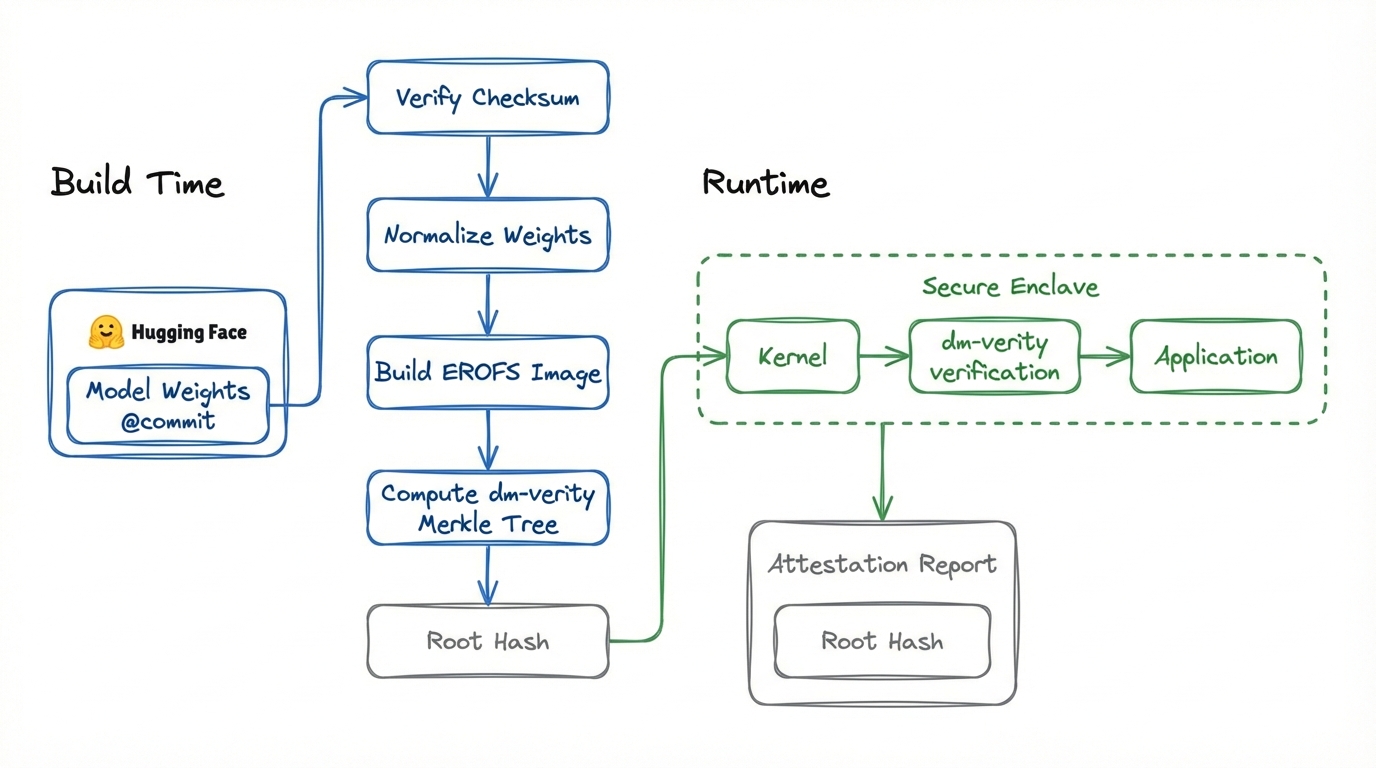
Modelwrap proceeds in three phases:
1. Computing the model weight commitment
Modelwrap first downloads the model weights at a specific version. It then computes a Merkle hash tree (using dm-verity) and outputs the root hash as the public commitment. Anyone can run Modelwrap themselves to ensure that the root hash corresponds to the right model weights.
This commitment is provided to the kernel when booting a new secure enclave.
Deterministic download
Modelwrap takes a Hugging Face model with an explicit commit hash:
Modelwrap downloads the model files, verifies them against Hugging Face's checksums, and normalizes the directory structure so rebuilds are reproducible.
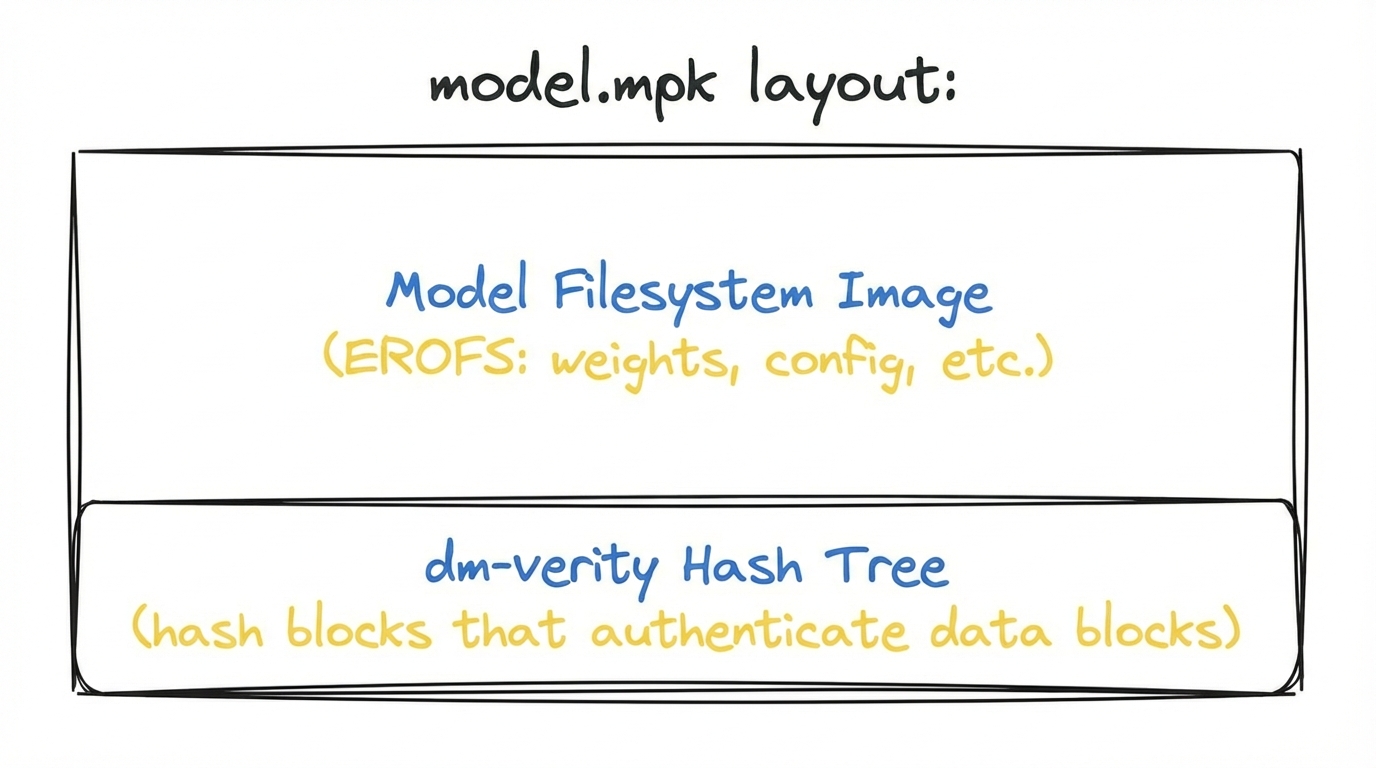
Build the image
The downloaded weights become an EROFS image—a Linux filesystem optimized for read-only, immutable data (dm-verity requires read-only).
Compute the root hash
Modelwrap uses veritysetup, a dm-verity utility, to build a Merkle tree over
the EROFS image, and compute the root hash. This is bundled together with the
image into a single modelwrap (.mpk) file for distribution.
2. Bind the commitment to the kernel
The Merkle tree root hash computed in the previous step is supplied to dm-verity via the kernel command line. Since the enclave measurement includes the kernel command line, the enclave attestation now covers the hash tree and, transitively, all model weights and configurations.
Even though the weights haven't actually loaded yet, the enclave has been committed to the weights that will be loaded, as dm-verity will ensure only the right model weights pass verification at runtime.
3. Enforcing this commitment
When vLLM loads the model, it reads the weights from disk. During this process, dm-verity intercepts every disk read, verifies the block against the attested root hash, throwing an error if even a single bit of the disk does not correspond to the committed weights. Importantly, this is all done automatically without requiring any changes to vLLM or the inference server code. This means Tinfoil can use unmodified upstream software rather than maintaining forks or patches that would have to be independently verified.
Verifying Public vs Private Models
For public models, anyone can verify. This is because anyone can download the same Hugging Face commit, run Modelwrap, check that your root hash matches the one in the attestation report. If it matches, you know the enclave is running exactly those weights.
If you've fine-tuned a model or trained something proprietary, you probably don't want to publish the weights. But you might still want to run it in a verifiable enclave.
Modelwrap handles this case too! You build the image yourself from your private weights. The root hash goes into your enclave config and shows up in the attestation report. If you swap weights, the hash changes. If the infrastructure tampers with the image, verification fails. Your users can verify that they're getting the same model every time, even without seeing the weights themselves. If you also want to keep the weights private from Tinfoil, you can encrypt the disk with dm-crypt and only give the key to the attested enclave at runtime.
Alternative Approaches
It's helpful to contextualize Modelwrap relative to other solutions we could have used to provide verifiability. Here we cover some natural approaches we considered and why we found them lacking in our use cases.
Why not bake weights into the VM image?
Modelwrap allows us to achieve the same result but with added flexibility! Much of the VM image contains infrastructure for booting the enclave and serving data which is common across different models. Using Modelwrap, we can take a more modular approach by maintaining a single VM image for the infrastructure stack and plugging in many different models.
Additionally, beyond creating the disk image, Modelwrap reproducibly packages weights and configurations such that public models can be independently verified.
Why not just sign the model files?
Tools like Sigstore Model Transparency let you cryptographically sign model weights and verify the signature after downloading. While this is useful for proving authenticity at the moment the data is checked, signature verification does not protect the data while it is in use.
Tinfoil adopts a stronger threat model where a malicious hypervisor can tamper with the disk contents after the signature is verified. Modelwrap's approach with dm-verity checks the data's integrity as it is loaded into the enclave by verifying every read operation.
Performance
How much does verification cost? We benchmarked Modelwrap on three models ranging from 549 MB to 554 GB.
Storage overhead is minimal: the dm-verity hash tree adds about 0.8% to
the image size regardless of model (in our benchmarks). dm-verity computes a
Merkle hash tree of arity 128, creating little variance in storage overhead
across realistic model sizes.
Build time scales with model size. Most of the time is spent writing the EROFS image and computing hashes. We note that this is a one-time cost.
| Model | Size | Build time |
|---|---|---|
| Gemma 3 270M | 549 MB | 5s |
| GPT-OSS-120B | 183 GB | 4m 5s |
| Kimi K2 | 554 GB | 13m 25s |
Model loading overhead is what matters at runtime. We measured cold-cache reads of all model files—the worst case, where every block hits disk and gets verified:

On fast NVMe, cold-cache loading takes ~80% longer with verification—but this only affects initial model loading (typically once at server start). Once the model is loaded into GPU memory, dm-verity is out of the path and inference runs at full speed. Linux 6.19 also includes dm-verity optimizations that provide a roughly 35% improvement in cold-cache reads which we are planning to leverage soon.
Try It Yourself
Modelwrap is open source: github.com/tinfoilsh/modelwrap.
The root hash in the .info file is your cryptographic commitment to exactly
which model runs in your Tinfoil enclave. This maps to the same commitment
in the corresponding Tinfoil model config file, so you can be sure you're
talking to the right model. You can use this to verify a Tinfoil deployment,
or to generate a commitment for private weights to use in your own enclave.
Subscribe for Updates
RSS FeedStay up to date with our latest blog posts and announcements.